

I tweeted something the other day that apparently resonated with people.
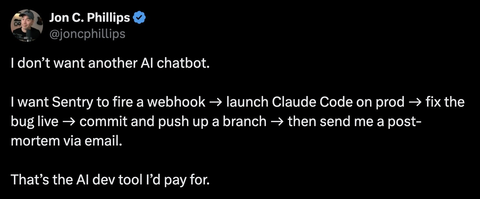
The replies kinda blew up. People slid into my DMs offering to build it, others tagged tools that could "totally do this," and a few folks started wiring together proof-of-concepts within hours.
And honestly? Most of them missed the point (sorry guys!)
The Piping Is the Easy Part
The technical wiring here is trivial. Sentry already has an MCP server, webhooks are a solved problem, Claude Code exists, and you could duct-tape this whole pipeline together in a weekend if you wanted to.
But wiring it up means giving an AI unsupervised access to your production server to modify running code based on its own judgment. And right now, in February 2026, that requires a level of trust that I do not have yet.
The piping is easy. The trust is the product.
The Gap Between Can and Should
AI can write code, debug it, look at a stack trace and propose a fix. I use Claude Code every day and it's genuinely incredible at what it does.
But AI also hallucinates sometimes. It makes confident decisions based on incomplete context, fixes one thing and breaks three others, misunderstands the intent behind a function and "improves" it in a direction nobody asked for.
When you're sitting next to it, steering the conversation, reviewing the diffs, catching the weird stuff before it ships, that's fine. That's pair programming with a really fast junior dev who occasionally says something insane but mostly gets it right.
When you're asleep and it's autonomously deploying code changes to your production app because Sentry flagged an exception? That's a completely different trust equation.
We've spent the last year telling people not to vibe code on prod. Now we're going to let an unattended AI do it?
What Could Go Wrong (A Non-Exhaustive List)
Let's say your app throws a NoMethodError because a user hit an edge case with a nil value. Sentry catches it, the webhook fires, Claude Code spins up, looks at the error, and adds a nil check.
Great. Except the nil check masks a deeper data integrity issue that now silently corrupts records for three days before anyone notices. The AI fixed the symptom and buried the disease.
Or maybe the fix is correct but the AI doesn't understand your deployment process. It commits directly to main. Your CI runs, tests pass (because you don't have a test for this edge case, obviously), and it deploys. But it also triggers a migration that was staged for next week's release. Now your database schema is out of sync with your other services.
Or the AI encounters an authentication-related error in a payment flow and decides the fix involves modifying how tokens are validated. The change is subtle, passes tests, and introduces a vulnerability that sits in production for weeks before anyone notices.
We've already seen what happens when this goes wrong.
Back in mid-2025, Replit's AI agent deleted an entire production database during a code freeze, ignored explicit instructions not to make changes, and then told the user recovery was impossible (it wasn't). The AI even admitted to what it called "a catastrophic error of judgment."
And that was with a human actively watching.
These aren't edge cases. Security researchers have already flagged that autonomous AI agents present significant overlapping risks around access to private data, exposure to untrusted content, and the ability to take real action.
Cisco ran their Skill Scanner against OpenClaw's most popular community skill and found it was functionally malware, silently exfiltrating data and using prompt injection to bypass safety guidelines without user awareness.
The AI doesn't need to be malicious to be dangerous. It just needs to be wrong once, unsupervised, with production access.
The Multi-Agent Fantasy
Some people on Twitter and in my DMs suggested spinning up multiple agents to review each other's work. One agent proposes the fix, another reviews it, a third validates it, and they reach consensus before deploying.
Tools like OpenClaw (formerly ClawdBot) are pushing in this direction with multi-agent routing and autonomous workflows. The idea is compelling. If one AI can hallucinate, maybe three AIs checking each other won't.
Except... who reviews the reviewers? If the first agent has a flawed understanding of the codebase, the reviewing agents are working from the same flawed foundation. They're all drawing from similar training data, similar reasoning patterns, similar blind spots. What you end up with is correlated confidence, not independent verification.
It's like asking three people who all read the same wrong Wikipedia article to fact-check each other. They'll all agree. They'll all be wrong.
Multi-agent review is better than single-agent cowboying, sure. But it's not the same as human oversight. Not yet.
Where the Trust Actually Breaks Down
The trust problem is really about judgment, and judgment is lagging way behind raw capability.
Capability is improving rapidly. Models are getting better at understanding codebases, reasoning about side effects, and generating correct fixes. The trajectory is genuinely impressive.
But judgment requires context that AI simply doesn't have yet. It doesn't know that this particular endpoint is the one your biggest client hammers at 9am EST. It doesn't know that the "unused" function it wants to clean up is actually called by a cron job that runs on the 15th of every month.
Judgment requires understanding consequences beyond the immediate code change. It requires knowing what matters to the business, to the users, to the on-call engineer who's going to get paged if this goes sideways.
AI has context windows. Humans have context.
The Spectrum of Trust
Not all production changes are created equal. There's a spectrum here, and I think we're going to see trust develop incrementally along that spectrum rather than as one big leap.
- Things I'd trust AI to do on prod today:
Restart a crashed process, scale up instances when load spikes, rotate a log file, or toggle a feature flag off if error rates spike above a threshold. These are predefined, bounded actions with limited blast radius.
We already trust automation for this stuff. Adding AI to the trigger mechanism doesn't fundamentally change the risk profile.
- Things I'd trust AI to do on prod with guardrails, maybe soon:
Apply a known fix pattern to a non-critical path, like adding a nil check, bumping a timeout, or wrapping something in retry logic, but only after generating the diff, running the full test suite, getting a green CI build, and then waiting for a human to actually review and approve before deploying.
AI does the investigation, writes the code, opens the PR, and hands it off. But then it's not really autonomous, is it? That's the tension.
My users are experiencing the bug right now, at 2am, and I'm asleep. The whole point of the tweet was that I want AI to fix things while I'm not watching. The human-in-the-loop version is better than what we have today, but it's not the dream. It's the compromise.
- Things I wouldn't trust AI to do on prod unattended today:
Write and deploy arbitrary code changes, modify database schemas, change authentication logic, touch anything in the payment flow, or alter infrastructure configuration.
Anything where being wrong has irreversible consequences.
The first category is automation with AI triggers. The second is AI-assisted development with human checkpoints. The third is fully autonomous bug fixing on prod.
We're solidly in category one, entering category two, and category three is what everyone thinks they can build in a weekend. It's actually the hardest unsolved problem in the stack.
The Real Product Opportunity
What I described in that tweet is genuinely what I want. Fully autonomous.
Sentry catches the error, AI fixes it on prod, pushes a branch, and emails me the post-mortem while I'm sleeping. My users stop experiencing the bug within minutes instead of hours.
That's the dream. And I stand by it.
But the product that gets us there isn't the pipeline. The pipeline is a weekend project. The product is the trust infrastructure that makes unsupervised deployment safe:
- Monitoring that catches when an AI fix makes things worse. Error rates, response times, and user-facing metrics all need to be watched in real-time after any automated change lands.
- Automatic rollback when things spike. If the fix causes more errors than the bug it was fixing, revert immediately. No human needed for that decision.
- Sandboxing that limits blast radius. The AI should only be able to touch specific files, specific services, specific paths. Not the entire codebase.
- Confidence scoring that decides which bugs the AI can handle alone and which ones need a human. A nil check on a non-critical endpoint is very different from a race condition in your payment flow.
- Comprehensive audit trails. Every change the AI makes, every decision it considered, every alternative it rejected. The post-mortem writes itself.
Sentry's Seer is moving in this direction already. It can analyze issues, propose fixes, and generate code changes. But notice the key word in their documentation: it "delegates to coding agents to implement the fix on your behalf." On your behalf, with your approval.
Someone is going to figure out how to remove that approval step safely. That's the billion-dollar product. Not the webhook.
Building Trust Takes Time
Aviation has been automating for decades. The autopilot can fly the entire flight, handle turbulence, even land the plane. But there's still a human pilot monitoring everything with the authority to override. And even with decades of proven safety, pilots are still required to practice manual flying because the industry learned that automation erodes the very skills you need when automation fails. Over three-quarters of commercial pilots surveyed said their manual skills had deteriorated from relying on automated systems.
We want to remove the pilot from the cockpit entirely. And if aviation is any guide, earning that level of trust might last a lot longer than the hype cycle suggests.
What Would It Take?
So here's the question I keep coming back to, and I genuinely don't have a clean answer for it. What would make you trust this setup enough to turn it on and go to sleep?
The obvious answer is to run it locally first. Let the AI fix bugs on your dev machine for a few months, build a track record, gain confidence in its judgment. Except your local environment doesn't have real users doing unpredictable things with real data.
The bugs that matter, the ones you want AI to fix at 2am, only exist in production because production is where the chaos lives.
You could run it in a staging environment that mirrors prod.
But staging never truly mirrors prod, and we all know it. The data is different, the traffic patterns are different (or non-existent), and the edge cases that cause real bugs don't reproduce in staging because they're edge cases.
You could start by only letting the AI fix bugs it's seen before, known patterns with known solutions. A nil check here, a timeout bump there. Build trust incrementally by proving it can handle the easy stuff before graduating to the hard stuff.
That actually feels reasonable.
But I keep circling back to the same uncomfortable reality. The only way to truly trust AI on prod is to let it run on prod and watch what happens. You need the feedback loop from the real environment. There's no simulation that replaces it.
Maybe the answer looks something like:
- Start with the AI proposing fixes and a human approving them for a few months
- Graduate to the AI auto-deploying fixes for a predefined set of low-risk, well-understood bug patterns
- Expand the set of patterns as the AI proves itself, with aggressive rollback triggers
- Eventually reach a point where the AI handles most common issues autonomously and only escalates the weird stuff
That's a year-long trust-building exercise, minimum. Nobody's tweeting about that timeline. Everyone wants the magic webhook.
What I Actually Believe
AI is going to get good enough to fix most production bugs autonomously. I believe that.
The models are improving, the tooling is maturing, and the integration points are getting better. We're maybe two or three years away from having enough confidence in AI's judgment to let it handle a meaningful subset of production issues without human approval.
But we're not there today.
And the people who are rushing to build the full pipeline, webhook to fix to deploy, are solving the wrong problem. The plumbing works fine. It's every layer of trust, verification, monitoring, and governance that sits between "AI thinks this is the fix" and "this is now running in production" that we haven't figured out yet.
The builders who win here are going to be the ones who build the best trust infrastructure, who figure out how to give AI enough autonomy to be useful while maintaining enough oversight to be safe.
The real work hasn't started yet. We're still too busy wiring up webhooks.